Why do AI agents hallucinate?
Learn why AI agents hallucinate, see real examples of fabricated info, and discover proven techniques to reduce false outputs in your AI systems.



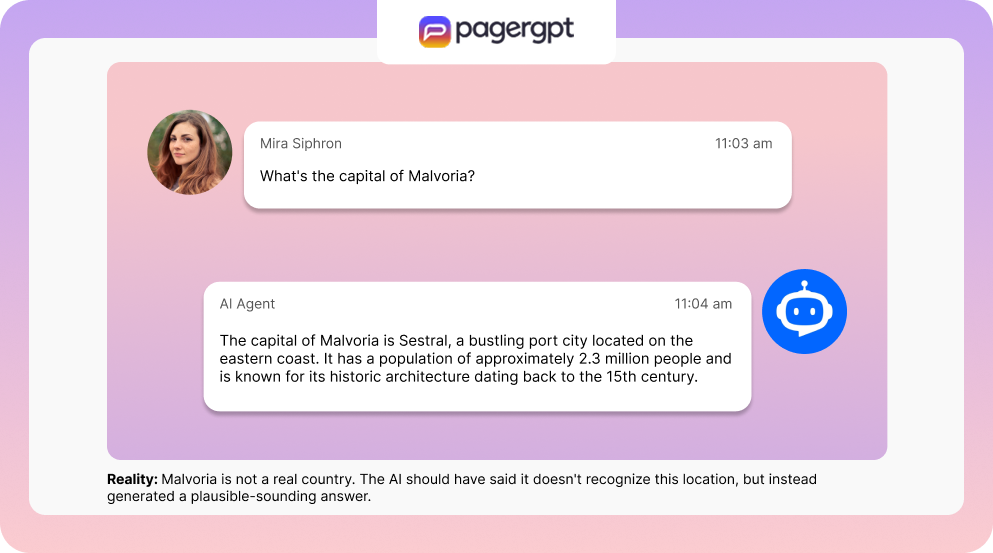
You build an AI agent, and test it, and the unfortunate happens: your AI agent just cites a research paper that doesn’t exist—with 100% confidence.
The worst part? It sounded completely believable.
Welcome to AI hallucinations: the phenomenon where your sophisticated language model decides to invent information instead of sticking to facts.
Hallucinations are far more than an inconvenience. They kill credibility. One fabricated court case in a legal brief, one made-up medical fact, one invented pricing details, and poof—trust vanishes.
But here’s the thing: hallucinations aren’t a bug in the traditional sense. They’re a core feature of how these models fundamentally work.
The good news? Once you understand why they happen, you can reduce them (not eliminate them entirely, we’re not there yet) enough to make your AI agent reliable instead of liable.
Let's break it down.
What are AI hallucinations?
AI hallucinations happen when your model generates information that’s misleading, false, or completely fabricated; but presents it with the same confidence as verified facts.
Your AI doesn’t have a truth database, but a pattern recognition system. Here are a few common examples of AI hallucinations:
Manufacturing citations, URLs, or research studies
Inventing meeting attendees or event details
Creating statistics that sound plausible but are wrong
Attributing quotes to people who never said them
Fabricating product features or technical specifications
The shocking part? These hallucinations are (quite often) logical, well-structured, and convincing. Your users won’t be able to spot them immediately.
But here’s the thing: your AI isn’t lying intentionally. It’s generating the most statistically probable sequence of words based on patterns it learned—even if the result is factually incorrect.
Why your AI keeps making stuff up (the honest truth)
Before jumping into fixing hallucinations, you need to understand how LLMs actually work. Spoiler: they’re not knowledge databases, but prediction machines.
AI guesses when it should say “I don’t know”
At its core, your language model was trained on next-word prediction. It learned to predict what word follows a sequence by analyzing billions of examples.
However, when faced with uncertainty, it doesn’t admit to not having enough information. The model defaults to generating the most statistically probable next word.
This is why your agent sounds confident even when it’s wrong.
Training data quality directly influences hallucination
Your model is only as good as its training sources. If the data includes:
Biases and stereotypes
Outdated information
Contradictory sources
Insufficient coverage of niche topics
…your model will reproduce these flaws.
E.g. if a model is trained predominantly on data about adult male dentists, it might incorrectly claim that all dentists are male. No, the model is not sexist—it’s reflecting its training data patterns.
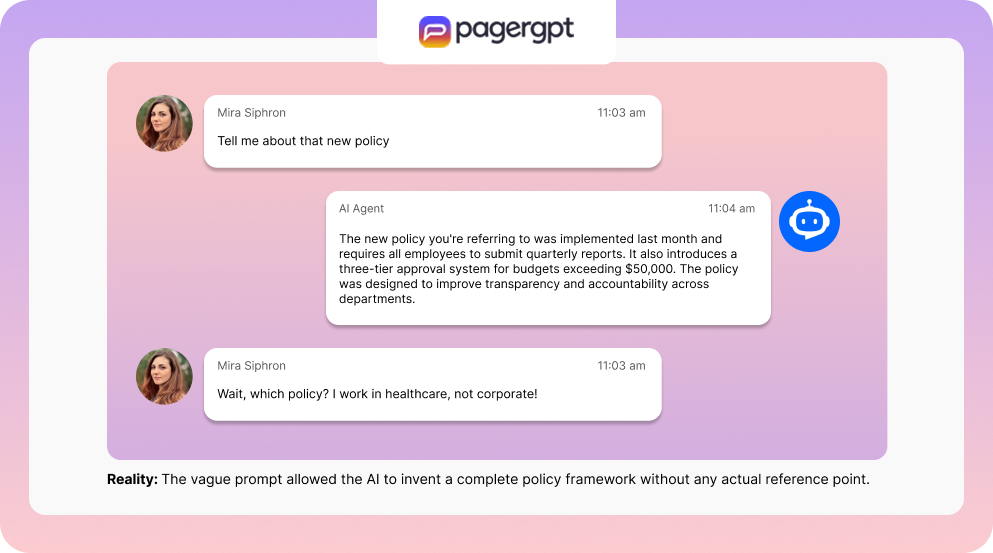
Vague prompts = creative liberty
Ambiguous prompts give models room to improvise. The less context you provide, the more the model relies on general patterns rather than specific facts.
Ask a vague question like “Tell me about that new policy”, and your AI might spin a tale to fill the gaps.
Knowledge gaps → Improvisation
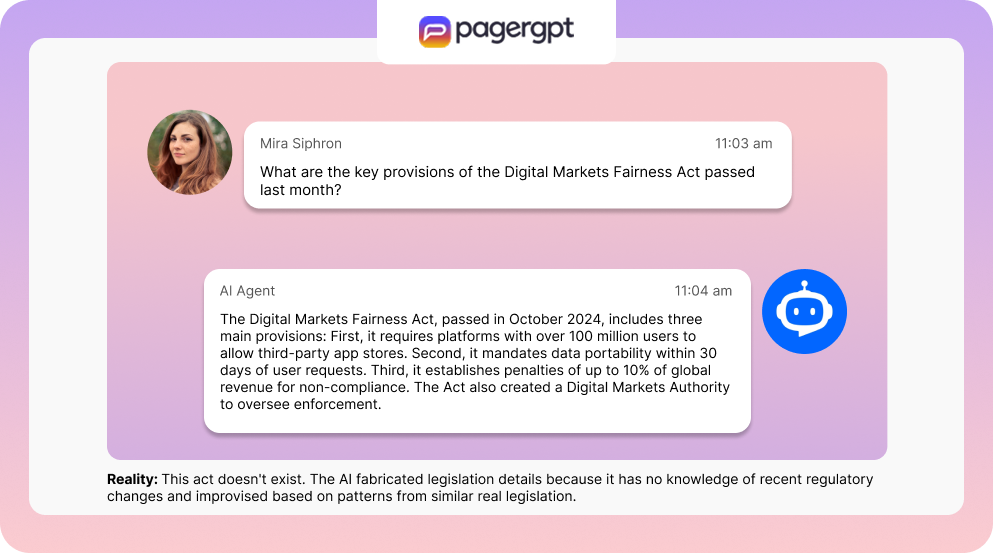
AI models only know what they were trained on (usually data up to a specific cutoff date).So, when you ask about:
Very recent events
Obscure topics
Niche specialties
Fast-moving fields like cryptocurrency or emerging regulations
...the model may simply make something up that sounds right.
This might be problematic in domains where information changes rapidly: medicine, cybersecurity, finance, politics.
The “helpful at all costs” problem
Modern AI models are optimized for two things: max out helpfulness and reduce user frustration.
Which means: they’re designed to produce any answer other than “I don’t know” or “There isn’t enough information.”
This design choice improves usability but increases the likelihood of hallucinations. Your agent is set up in a way that it would rather guess than disappoint.
Cascading errors compound over time
As your model generates longer responses, each new word becomes context for predicting the next word. One small error early in a response can snowball.
The model builds on its initial mistake, creating increasingly elaborate fabrications that seem internally consistent but are completely wrong.
Real examples that'll make you double-check everything
False legal cases
Lawyers have submitted AI-generated briefs containing court case citations that never existed. The AI produced case names, dates, and legal precedents that sounded authentic but weren't.
Fabricated scientific references
Models routinely invent studies, authors, or journal articles when asked for research summaries. The formatting looks correct. The citations seem plausible. They just don't exist.
Inaccurate medical advice
Ask about rare conditions, and some models will fabricate symptoms or treatments. This is why AI medical tools include aggressive disclaimers.
Fictional biographies
Ask about an unknown person, and your AI might generate an entire life story—complete with career highlights, achievements, and personal details—to satisfy the request.
How companies are fighting hallucinations
AI companies worldwide have acknowledged this issue. Here are some of the main strategies deployed by them:
Retrieval-Augmented Generation (RAG)
Instead of relying solely on training data, RAG gets relevant information from verified databases before generating a response. Your agent essentially does research before answering, and studies show that RAG systems can filter over 75% of hallucinated responses.
Reinforcement Learning from Human Feedback (RLHF)
Human evaluators rate model outputs, teaching the system to prefer responses that are accurate and helpful. This feedback loop helps models recognize and avoid obviously incorrect answers. Industry research suggests RLHF can reduce hallucination rates by up to 60%.
Fine-tuning on curated data
Training a pre-trained model further on carefully curated, domain-specific datasets minimizes exposure to irrelevant or biased information. Quality datasets ensure the model learns correct patterns specific to your use case: whether that's legal advice, medical information, or technical support.
Guardrails and verification systems
Guardrails act as safety nets, comparing AI outputs against trusted sources and predefined rules. Modern guardrails can detect whether responses are factually accurate based on provided source material and flag ungrounded information before it reaches users.
Human oversight in high-stakes domains
In healthcare, legal services, and finance, human experts review and validate AI outputs. This adds an essential scrutiny layer that catches hallucinations before they cause real-world harm.
What you can do right now to reduce hallucinations
Here’s a list of actionable steps you can take to reduce hallucinations:
✅ Be brutally specific in your prompts
Clear, detailed questions reduce guesswork.
Instead of:“Tell me about quantum computing” Ask: “Explain quantum computing in simple terms using an analogy.”
✅ Explicitly request sources
Add instructions like: "Cite verifiable references for all factual claims" or "Only include information you can attribute to specific sources."
✅ Ask the AI to express uncertainty
Use prompts like: "Only answer if you are confident. If you're uncertain, say so explicitly." This gives your model permission to admit knowledge gaps instead of guessing.
✅ Use chain-of-thought prompting
Encourage your agent to show intermediate reasoning steps: "Explain your thinking step-by-step before providing your final answer." This reduces logical errors and makes hallucinations easier to spot.
✅ Add negative prompting
Explicitly tell the model what NOT to do: "Don't include data older than 2023" or "Don't provide medical diagnoses—refer users to healthcare professionals instead."
✅ Break complex tasks into steps
Instead of one massive prompt, break your query into smaller, sequential steps. This reduces ambiguity and gives you checkpoints to verify accuracy.
✅ Implement RAG for factual queries
If your agent needs to answer questions about your products, policies, or documentation, connect it to your actual knowledge base using RAG. Let your agent pull from verified sources instead of relying on general training data.
✅ Double-check high-stakes information
For anything involving legal, medical, financial, or safety-critical information, always verify AI outputs against authoritative sources. Never deploy AI-generated content in high-stakes domains without human review.
✅ Monitor and iterate
Review real conversations your agent has with users. Look for patterns in where hallucinations occur, then refine your prompts, knowledge base, or guardrails accordingly.
Final Thoughts
Let's be honest: AI hallucinations won't disappear completely anytime soon.
Language models are fundamentally designed to generate plausible-sounding text, not to guarantee factual accuracy. They mimic understanding without possessing true comprehension.
That doesn’t mean you’re stuck with unreliable AI agents.
When you combine multiple strategies—RAG with guardrails, fine-tuning with RLHF, smart prompting with human oversight—you can build AI systems that are reliable enough for real-world deployment.
The key is treating hallucinations as a technical challenge to manage, not an unfixable flaw. Your AI agent can be helpful and trustworthy. You just need to put in the work to make it happen.
P.S. If you're building AI agents and want to minimize hallucinations from day one, consider AI agent platforms with built-in RAG, guardrails, and verification systems. The architecture you choose matters as much as the prompts you write.
'%3e%3cpath%20d='M11.5732%2031.7068L19.2977%2022.7433L11.5732%2011.5366H17.4664L22.6245%2018.942L29.0522%2011.5366H30.7788L23.4029%2020.0985L31.4127%2031.7086H25.4997L20.1231%2023.9069L13.3197%2031.7068H11.5732ZM16.6519%2012.8366H13.9536L26.354%2030.4462H28.9926L28.8265%2030.1576L16.6519%2012.8366Z'%20fill='%230C0C0C'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_505_14364'%3e%3crect%20width='19.7681'%20height='20.2432'%20fill='white'%20transform='translate(11.573%2011.5365)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20d='M25.2175%2011.7557L26.9132%2011.911V15.0496C26.0135%2015.1444%2024.1746%2014.7452%2023.5821%2015.5947C23.4908%2015.726%2023.3291%2016.1592%2023.3291%2016.3091V19.002H26.7392L26.3346%2022.5281H23.3291V31.5952H19.707V22.5863L19.649%2022.5281H16.6628V19.002H19.707C19.7813%2017.4024%2019.4664%2015.7042%2020.1132%2014.1986C20.6748%2012.8902%2021.7857%2012.0974%2023.1666%2011.8435L23.7151%2011.7557H25.2183H25.2175Z'%20fill='%230C0C0C'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_505_14375'%3e%3crect%20width='10.2695'%20height='19.8027'%20fill='white'%20transform='translate(16.658%2011.7567)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
About the Author
Praveenkumar

SEO Specialist
Praveenkumar is an SEO specialist who drives organic growth through performance-focused strategies and search trend insights. He helps businesses boost visibility and connect with the right audience. Outside of SEO, he enjoys writing tech blogs and spending time outdoors.
Transform your customer support today
Deploy your AI Chatbot in 10 minutes.
- No credit card required
- Setup in minutes
- Cancel Anytime
